Historically, it has taken the dedicated and fully committed singer 7 to 10 years of performing, combined with ongoing serious study with a competent teacher to become a virtuoso. A virtuosos has mastery over their voice under all conditions and will never have a vocal issue. Once achieved, you will always sound fully yourself, authentic, relaxed, natural and unique, without ever forcing or over-exerting, ever.
I went this route. It took me 10 years from professional acting school and then finding a master singing teacher and spending years in the voice studio and performing to become a virtuoso. Why did it take so long? (It is all in my book Intrinsic Singing– “one of those rare books that combines personal journey, expert instruction, and loving inspiration“…
This is a piece from my 1993 one man show in New York City entitled, “Love, Desire and Growing Pains” at the Avalon Theater. It will give you a sense of what I teach.
I had some unresolved trauma (mostly head injuries) that prevented me from using my emotional muscles and expression system the way is was designed, what I call the singer’s muscles, to maximum potential. I had some rehabilitation to accomplish before I regained the natural ease that Nature intends for our vocal apparatus and expression system which is all about building a society for our mutual benefit. Sophisticated, skilled bodywork and intrinsic exercise conditioning is key, as well as body training that would allow me to engage bone conduction of my voice as well as improving my right ear’s ability to control my voice (called the ‘performance ear’, all rooted on modern science).
Most of us do not understand the process of gaining mastery over our voice. It is a somatic embodiment process, or discovering how the full body actually generates vocal emission. It is NEVER forced, pushed, over-exerted, and we do not use a microphone in our training (only when you achieve competency in your voice production) because your body is your instrument, and like the cello, it is the body of the cello that vibrates, just like the skeleton of your body that you learn to vibrate. This is the resonance that makes a powerful voice; skeletal resonation. This is accomplished with total dynamic relaxation and intrinsic muscle skill (the singer’s muscles I call them in my book). It is all about acquiring the expertise in how to generate skeletal vibration without ever trying to control your larynx- which by the way is controlled by your inner ear & Central Nervous System. Anyone who tells you to do something with your larynx is misinformed- the science has been confirmed.
Training in what I call Intrinsic Singing consists of:
-body-mind embodiment training through singing, to learn to transcend the protective mechanisms that keep you from using your emotional muscles (singer’s muscles) in a fully unified and elastic manner.
-acquiring the sensory-motor skills that allow you to sing naturally without over or under exerting (usually due to unrecognized fear states)
-re-conditioning your body, so that the emotional layer of muscles (the singer’s muscles) are once again able to easily initiate and sustain vibratory influence throughout your skeleton. The extrinsic layer of muscles on the outside can never initiate movement in the case of a singer- only get in the way if there exists an imbalance between the smaller, interior & larger, exterior musculature. Only the intrinsics (which in this Western cultures are under developed) can initiate the dosing of air that we use to generate the skeletal vibration that we call singing.
-Learning to use the Italian Vowels in our singing. The Italian vowel is the most front placed vowel and it is highly efficient in emitting the vowel (open and free) vibration out into space, getting it to vibrate the room and individuals in that room. This happens outside your body, and never having to use tension of any sort to make it happen. Engagement and coordination yes; tension; no! This training is all about learning how the vocal apparatus actually functions in an engaged and dynamically relaxed manner and most importantly, energy conserving and energetically recharging manner. If you are not recharged after singing, you haven’t found it yet.
Developing a musical ear!
I will get to the point! IT IS YOUR EAR THAT SINGS (neurologically, if you know the physics).
Skeletal resonation of your voice:
The basis of a powerful, resonant singing voice
Today, I train singers & actors to find the voice that Nature intends for them that is unique and like no-one else’s. This is a physiological, uncovering process. As an actor who sings, I am capable of assisting you (through demo, hands-on training, and with other accelerating tools) in finding your authentic speaking voice that is the basis of your authentic singing voice. We must learn to work on your material first in story telling or what we can call acting. Then we can use that state as the basis of your authentic singing voice, because they are the same exact state.
Once accomplished, you can do whatever you wish with that new found instrument, You can sing as often as you like and you will never have an issue that you cause due to improper technique.
I do this by first assessing your listening profile because if you cannot make the bones of your skeleton to vibrate effortlessly, you will not ever achieve sonic return in your singing and this is the magnificent yet simple power of the human voice. We experience bone conduction of our voice much faster than we experience air conduction of our voice in space. In other words, it is bone conduction that enables the singer to put himself/herself in a self-listening mode- they are the first one to experience their own voice. Bone conduction operates much like a string instrument such as a cello, where the vibration of the vocal folds in the larynx (the cello strings) is transmitted through the bone structure (the body of the cello). This acheives what we call ‘sonic return’ or what my teacher Margaret called the ‘boom in the room’.
A MUSICAL EAR
A musical ear has to be able to attune itself to the entire sound spectrum. It must be capable of knowing how to perceive and analyze every part of the frequency spectrum with maximum speed and precision, and instinctively. (The range critical for musicality is in a bandwidth located between 500 Hz 4000 Hz called the singer’s formant).
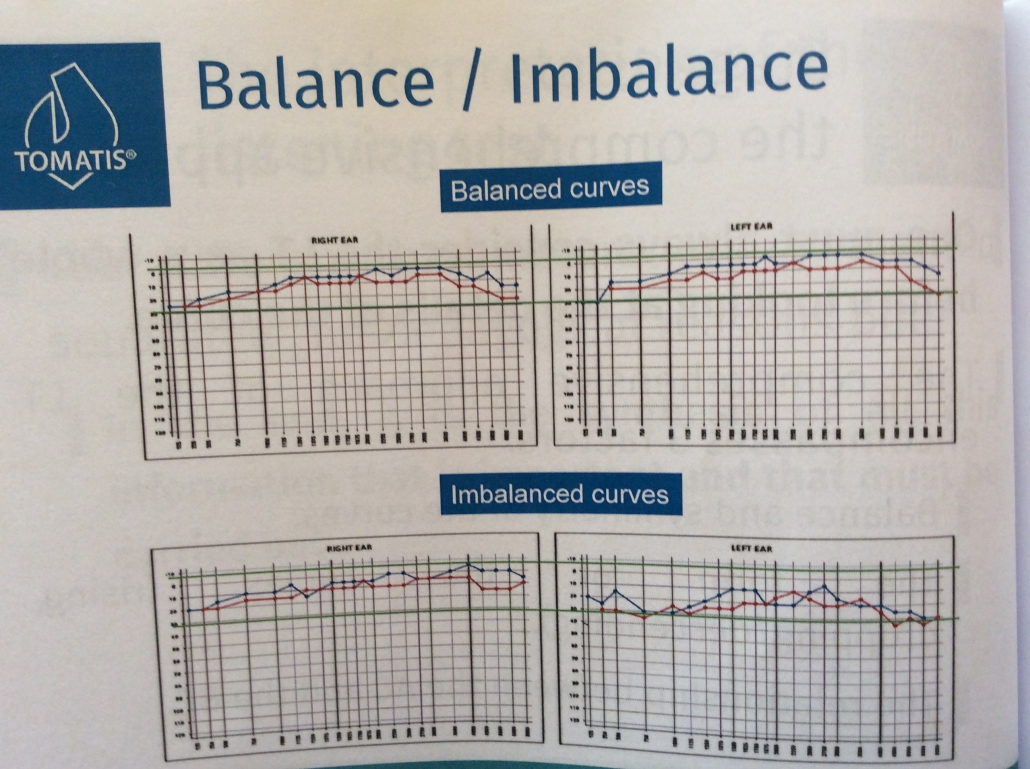
Your listening profile is a picture of how you listen in space (an act of will), way more than simply hearing (which is a passive act). Below is Dr. Alfred Tomatis (ear, nose and throat doctor or ENT) many decades experience of working with professional singers. The top “Balanced Curves” show someone’s listening profile that has an ease of expression and a good balance between how they hear their own voice through the air (tympanic membrane) and how they perceive their own voice in their skeleton (bone conduction and the basis of your authentic voice). This is called bone conduction (red line) and it 10 times faster than what we hear through the air. It is therefore the basis of your voice and most of us must be trained how to evoke and master it with somatic embodiment training. Without knowing how to generate this bone conduction, you will never achieve the voice of a virtuoso. And it cannot be done with force since the vocal folds are an INVOLUNTARY process.